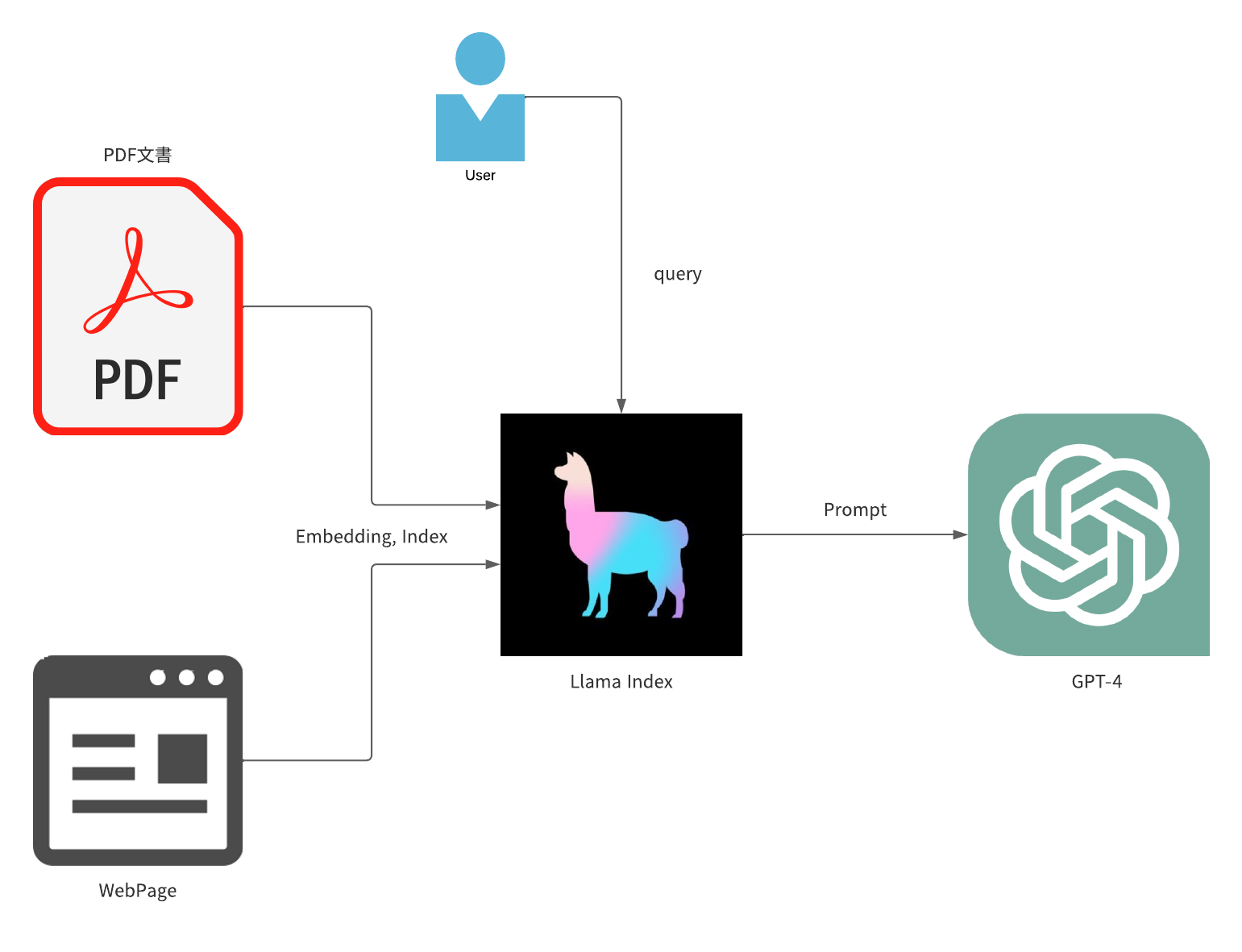
大規模言語モデルを使用するプロダクトに携われることになり学習を深めようと思い、Llama-Index を用いて GPT のプロンプトエンジニアリングをし論文や Web サイトに対してのクエリができるアプリケーションを作成しました。
構成
- Streamlit: Web アプリケーションの UI 作成
- Llama-Index: 文章のエンべディング(ベクトル化)、インデックス作成
- OpenAI GPT-4: クエリに対する文章の生成
Llama-Index について
概要
Llama-Index とは ChatGPT のプロンプトエンジニアリングをするためのライブラリであり、様々なローダーを使用しファイルや Web サイト、Slack などのアプリケーションなどから文章を取り出しその文章に対して質問することができます。
また文章の理解にはエンべディングを行っています。エンベディングは、テキストの単語をベクトルに変換します。ベクトルは、テキストの意味を数値で表し、これにより、LlamaIndex は、テキストの意味を理解し、関連するテキストを検索することができます。ChatGPT と組み合わせて使用することで、ユーザーのクエリに対するより適切で関連性の高い応答を生成することができます。
簡単にまとめると以下のフローで実行されます。
- ローダーで文章を取得
- 文章をエンべディング(ベクトル化)
- クエリに対して類似度の高い文章を検索
- 検索された文章を ChatGPT に入力し応答を生成
-
Roader について 様々な種類の Roader を使うことで多くの種類のファイルやアプリケーションから文章を取得することができます。 LlamaHub に使用できるローダーの一覧とコードがあります。
-
インデックスの作成 Llama-Index ではクエリに対する文章を検索する際にインデックスという概念が存在します。 インデックスの構成方法としてテキストを読み込んだ後チャンクという特定の文字数で文章を分割しそれぞれを Node と言われる構造体に格納します。その後、Node をエンべディングし、ベクトル化したものをインデックスとして保存します。
-
インデックスの種類 インデックスにも種類がありより文章の精度を上げるためにはクエリに対して適切なインデックスを選択する必要があります。
- List Index
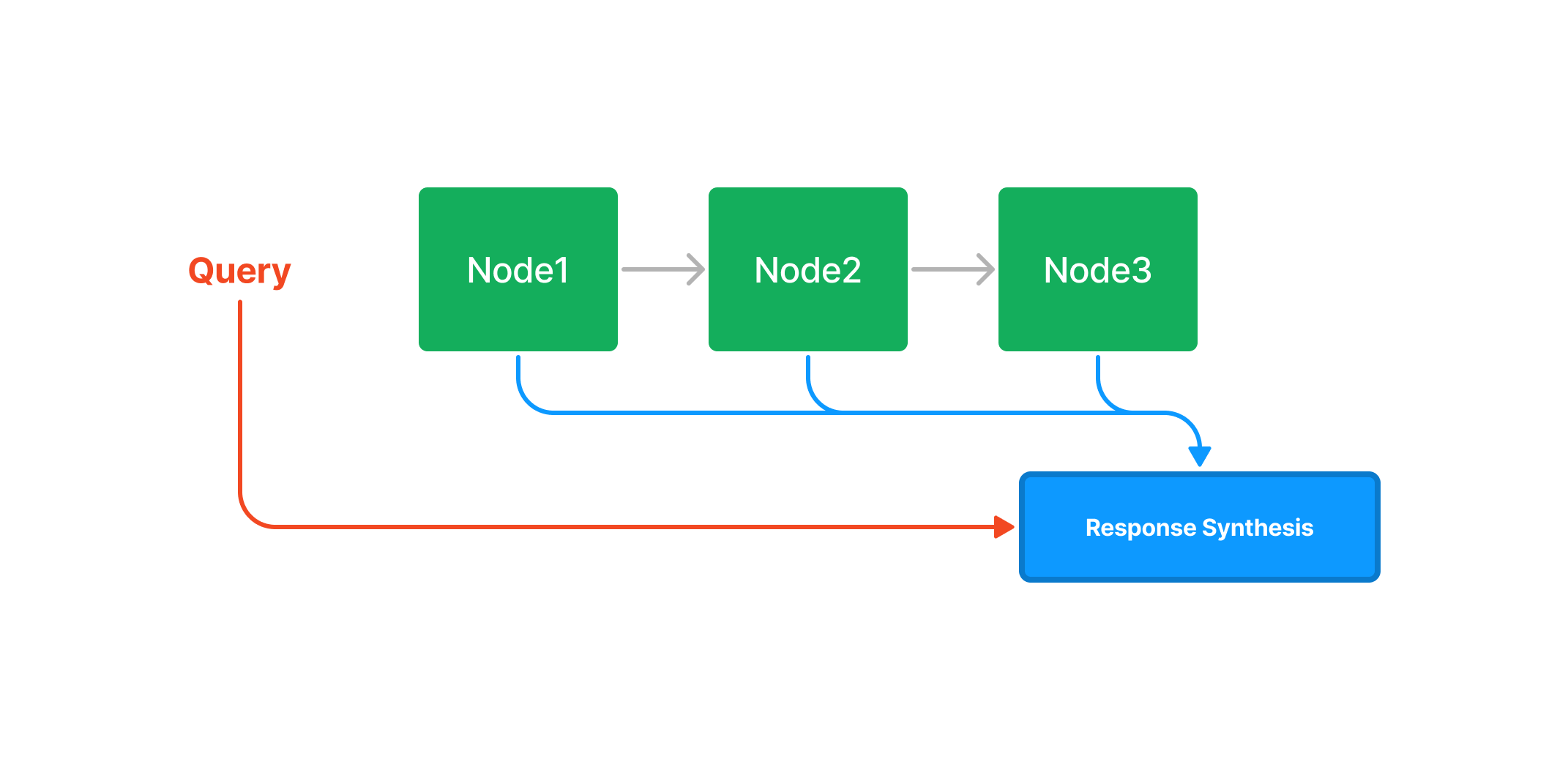 ListIndex ではノードのリストを作成し、クエリに対して先頭から処理していき出力を最後に合成する。
また上位 k 個のノードをに対して実行する方法や、ノードに対してキーワードフィルターを適用することもできる。
ListIndex ではノードのリストを作成し、クエリに対して先頭から処理していき出力を最後に合成する。
また上位 k 個のノードをに対して実行する方法や、ノードに対してキーワードフィルターを適用することもできる。 - Vector Store Index
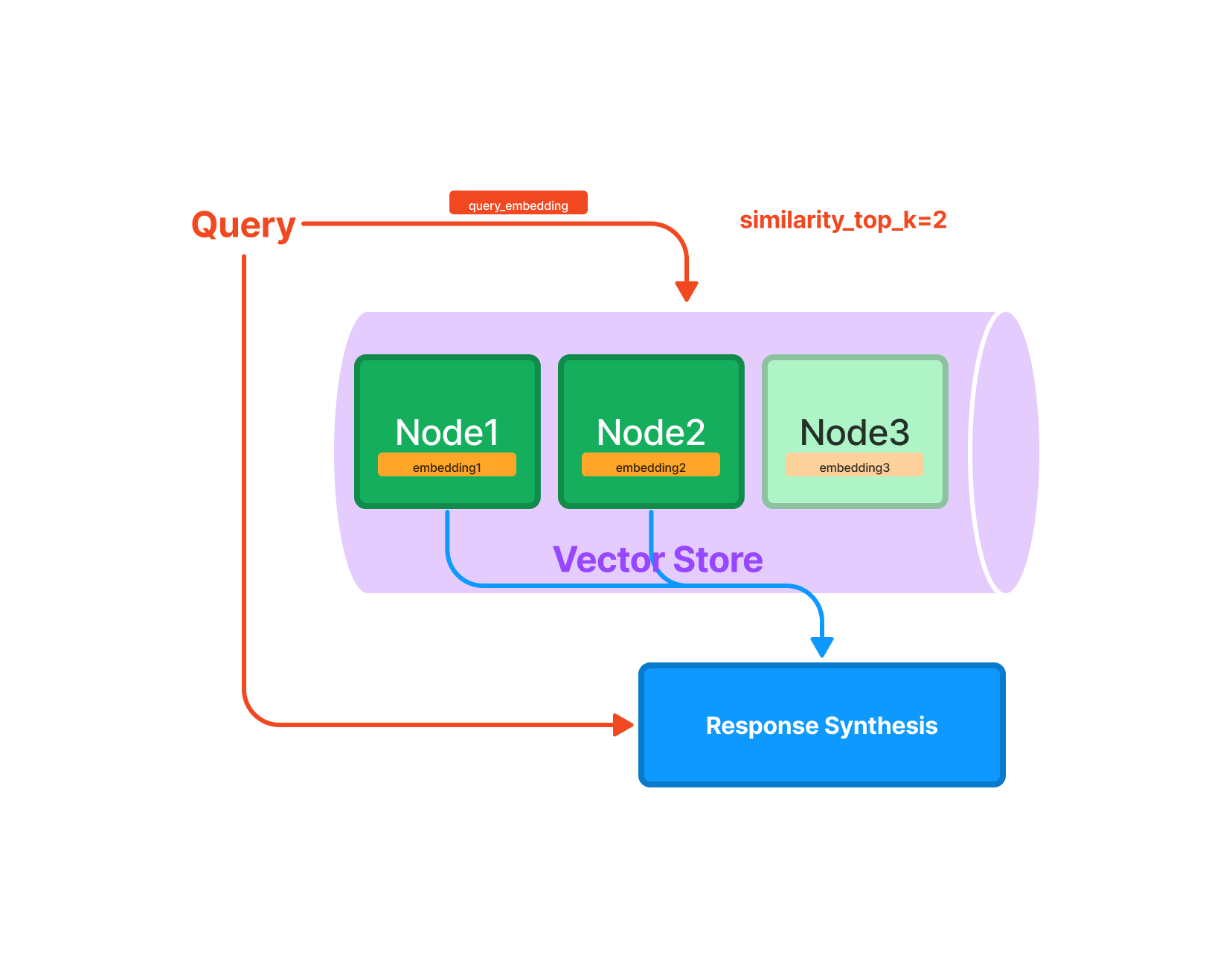 VectorStoreIndex ではノードと文章のベクトルを保持し、クエリに対してベクトルの類似度を計算し、類似度の高い上位 k 個のものを合成し出力する。
※よく使われる
VectorStoreIndex ではノードと文章のベクトルを保持し、クエリに対してベクトルの類似度を計算し、類似度の高い上位 k 個のものを合成し出力する。
※よく使われる - Tree Index
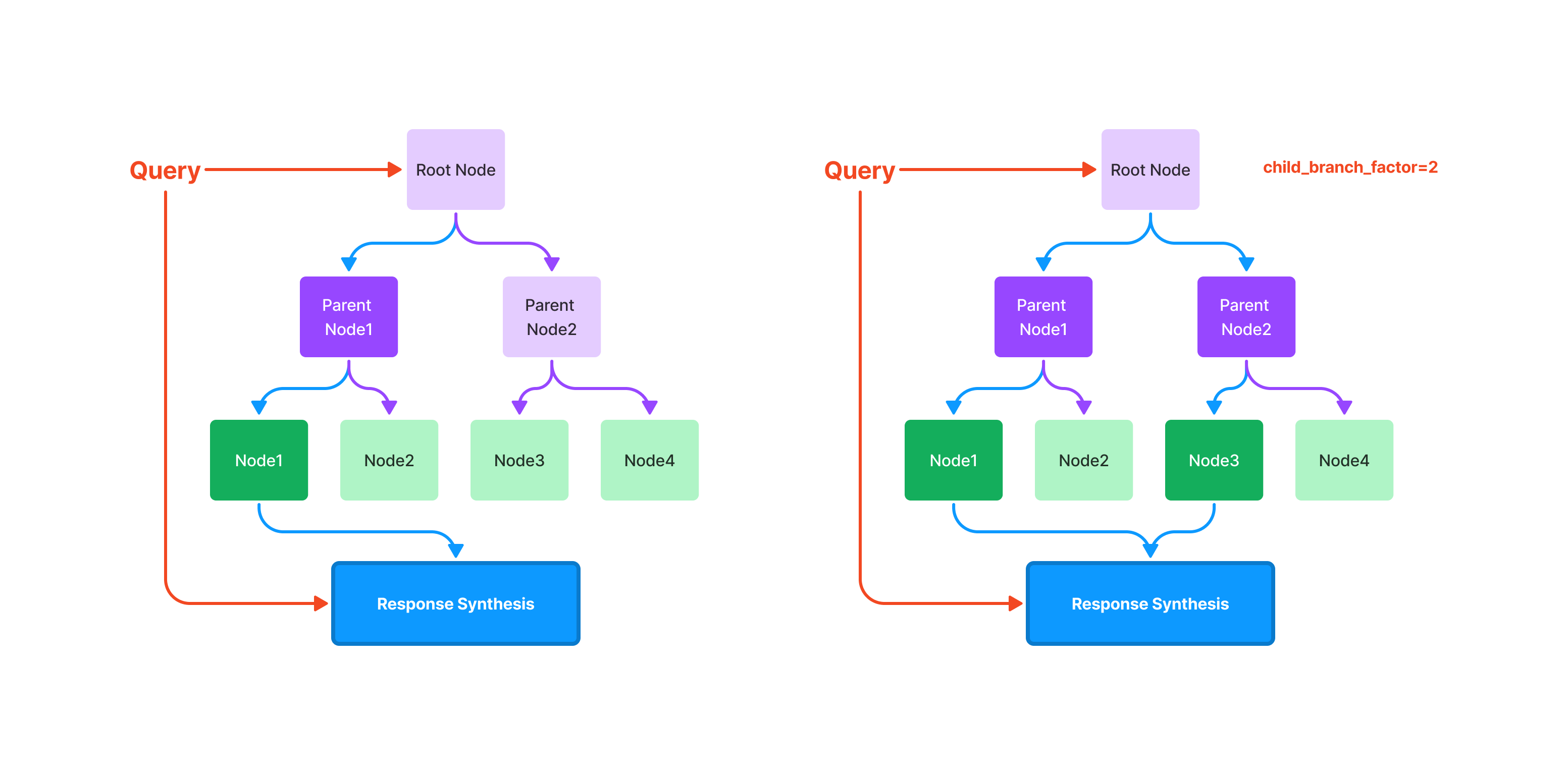 TreeIndex ではノードをツリー構造にし、クエリに対してツリーを探索し、類似度の高い上位 k 個のものを合成し出力する。使用する子ノードの数を指定できる。
TreeIndex ではノードをツリー構造にし、クエリに対してツリーを探索し、類似度の高い上位 k 個のものを合成し出力する。使用する子ノードの数を指定できる。 - Keyword Table Index
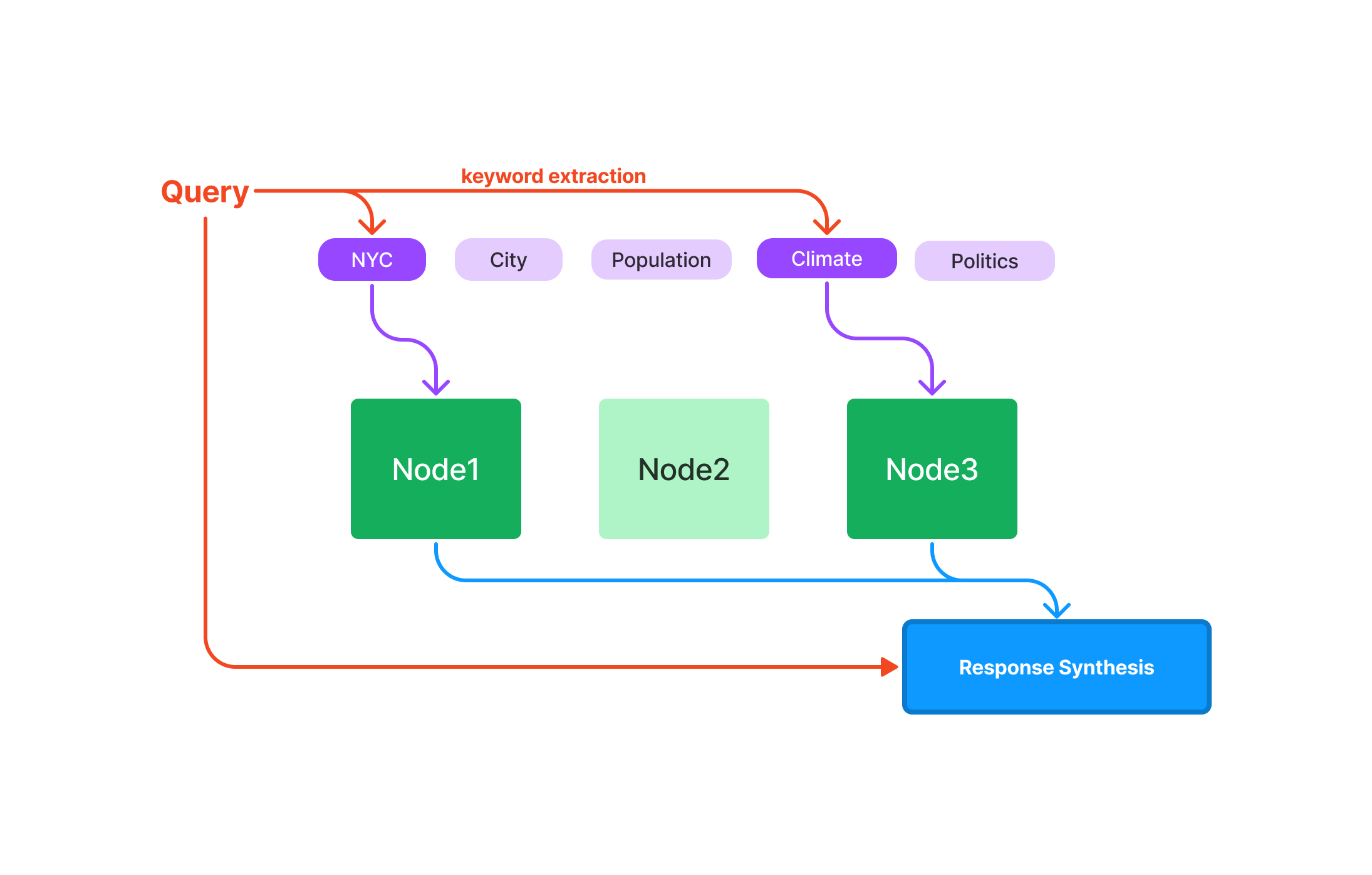 KeywordTableIndex ではノードとキーワードのテーブルを作成し、クエリのキーワードを使用しノードを選択し最終的に合成して出力する。
KeywordTableIndex ではノードとキーワードのテーブルを作成し、クエリのキーワードを使用しノードを選択し最終的に合成して出力する。
Llama-Index の実装
今回は PDF と Web サイトから文章を取得し、その文章に対してクエリを行うアプリケーションを作成しました。 インデックスには VectorStoreIndex を使用し、クエリに対して類似度の高い文章を検索し ChatGPT に入力し応答を生成します。
1import os
2import streamlit as st
3from pathlib import Path
4import tempfile
5from llama_index import download_loader
6from llama_index import GPTVectorStoreIndex, LLMPredictor
7from langchain.chat_models import ChatOpenAI
8
9os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY") # APIキーを環境変数から取得
10
11llm = ChatOpenAI(model_name="gpt-4") # GPT-4を使用
12llm_predictor = LLMPredictor(llm=llm)
13
14if __name__ == "__main__":
15 st.title("Llama Index")
16 select = st.selectbox("",("URL", "PDF")) # URLかPDFを選択
17
18 if select == "URL":
19 URL = [st.text_input("URLを入力してください")] # URLを入力
20 text = st.text_input("質問を入力してください") # 質問を入力
21
22 submit = st.button("送信")
23
24 if submit and len(URL) > 0 and len(text) > 0:
25 SimpleWebPageReader = download_loader("SimpleWebPageReader") # SimpleWebPageReaderをダウンロード
26
27 loader = SimpleWebPageReader()
28 documents = loader.load_data(urls=URL) # SimpleWebPageReaderを使用してURLからデータを取得
29
30 index = GPTVectorStoreIndex.from_documents(documents=documents, text=text, llm_predictor=llm_predictor) # Llama Indexを使用今回はVectorStoreIndexを使用
31 query_engine = index.as_query_engine() # クエリエンジンを作成
32
33 st.write(query_engine.query(text).response) # クエリに対する回答を表示
34
35 if select == "PDF":
36 file = st.file_uploader("PDFをアップロードしてください", type="pdf") # PDFをアップロード
37 text = st.text_input("質問を入力してください") # 質問を入力
38
39 submit = st.button("送信")
40
41 if submit and file is not None and len(text) > 0:
42 with tempfile.NamedTemporaryFile(delete=False) as tmp_file: # PDFを一時ファイルに保存
43 fp = Path(tmp_file.name)
44 fp.write_bytes(file.read())
45
46 CJKPDFReader = download_loader("CJKPDFReader") # CJKPDFReaderをダウンロード
47
48 loader = CJKPDFReader()
49 documents = loader.load_data(file=tmp_file.name) # CJKPDFReaderを使用してPDFからデータを取得
50
51 index = GPTVectorStoreIndex.from_documents(documents=documents, text=text, llm_predictor=llm_predictor) # Llama Indexを使用今回はVectorStoreIndexを使用
52 query_engine = index.as_query_engine() # クエリエンジンを作成
53
54 st.write(query_engine.query(text).response) # クエリに対する回答を表示streamlit を使用して簡単な UI を作成し、URL か PDF を選択し、質問を入力すると回答が表示されます。
実行結果
- URL に対する質問と回答
 OpenMV という MicroPython を使用したカメラモジュールのドキュメントに対して、RGB 画像からグレースケール画像に変換する関数について質問してみました。
正しい回答が返ってきていることが確認できます。
OpenMV という MicroPython を使用したカメラモジュールのドキュメントに対して、RGB 画像からグレースケール画像に変換する関数について質問してみました。
正しい回答が返ってきていることが確認できます。 - PDF に対する質問と回答
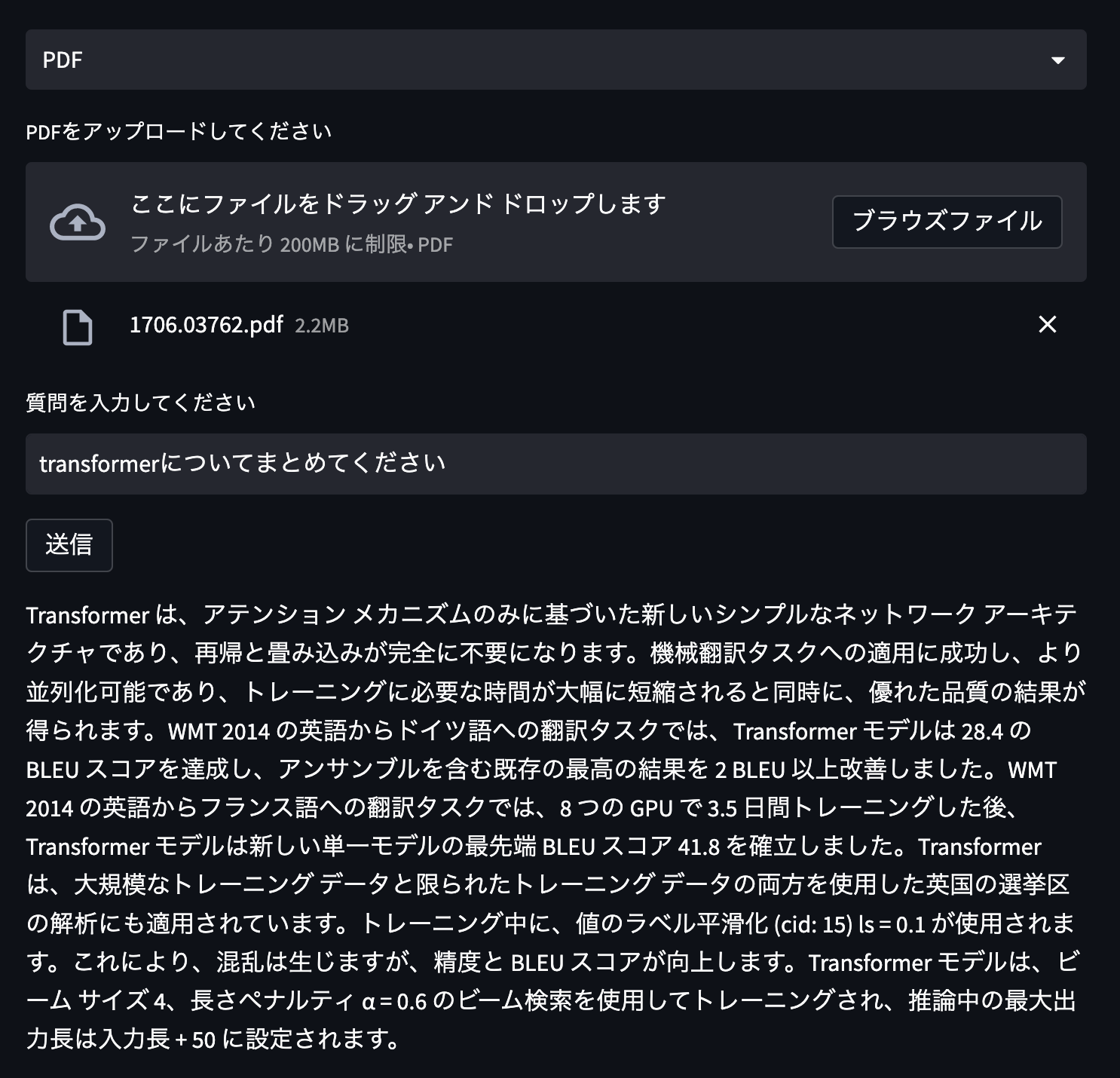 こちらは言語モデルの Transformer の論文を引用し Transformer についてまとめてもらいました。
こちらは言語モデルの Transformer の論文を引用し Transformer についてまとめてもらいました。
まとめ
今回は Llama Index を使用して簡単な質問応答システムを作成しました。 Llama Index は簡単に使用できてかなり便利なツールであるためこれからもお世話になることが多そうです。今後は LangChain なども併用していき、対話型にできるようにできたらなと思います。